

Is it still possible to scrape Facebook data? Yes. It is!


This post contains no code, but merely an experience I encountered lately.
In light of Facebook promises to protect their users data as a fallout of Cambridge Analytica debacle, Facebook revised its Graph API after suspending accesses to whole lot of endpoints for approximately a month and eventually released Graph API v3.0 on May 1, 2018.
Meanwhile, I was approached by a business owner asking me if I could help him out to create a scraping pipeline. Basically what he wanted was a process improvement on how his team works, an automated pipeline to scrape data from selected sources, process them and integrate them into existing system. So, I evaluated his requirements, made sure that I was able to deliver, and took the assignment. There wasn’t lots of challenges in terms of technical. What bothered me was the access to Facebook data. Despite the data being scraped are ‘publicly accessible’ data which are meant for public audiences, Facebook actually took down the Graph API endpoint on this particular resource.
No Graph API access == No access at all!? Not exactly.
First of all, I do not understand and I guess will never understand the rationale behind Facebook decision to take down the public info endpoint which you read it right! Public info, they are meant for the public audiences.
The tool I used was Scrapy, a fairly comprehensive and easy-to-use data scraping library in Python. What I did first is try to scrape facebook.com but I quickly realize most data are fetched asynchronously using AJAX. So, first attempt failed.
Then, I tried to scrape the data by mimicking the behavior of a user using Selenium. If you are not familiar with this, Selenium is essentially a tool to automate your browser, allow you to control and use your browser as if a human is using it. What my Selenium did was: Go to Facebook.com -> Login -> Search the keyword -> Start scraping while scrolling down. Well, that quickly caught the attention of Facebook and denied access to more data from their server. Yeah, Facebook is good at detecting bots.
I started to think about what if Facebook doesn’t keep sending my browsing behavior? Will Facebook be unable to detect if I’m a bot or a human? So I went to my browser settings and disabled JavaScript to see how Facebook works within that constraint.
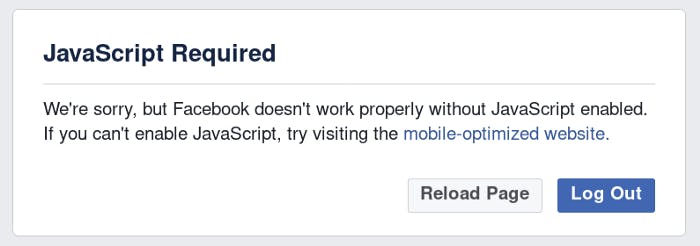
Facebook suggested me to try the ‘mobile-optimized website’ which it is actually the old-school mobile.facebook.com which doesn’t use any AJAX. This certainly reminded me of my high school time when smartphones were something rather modern and most of us were still relying on a compact phone. I did the same thing again, go to Facebook -> Login -> Search the keyword -> Start scraping and now it works!
Yes! Facebook is now harder to detect my browsing behavior, they can’t know which line I stopped at and reading at it or how many times I scrolled on that page, etc. Mobile Facebook works for my use case!
My last and working resort is to scrape on the classic Facebook. It works, although I won’t know how long will this trick lasts.
This is just an event happened on me lately. If you are facing similar issue, I hope this helps.
Thanks for the overwhelming responses, I afraid that I can’t make time for any task at the moment. However, your clap will definitely drive me further. If you like this post, feel free to give me a clap.
First published on 2018-07-07
Republished on Hackernoon